
关联分析是数据挖掘体系中重要的组成部分之一,其代表性的案例即为“购物篮分析”。我们以数据挖掘软件Clementine自带的一个购物篮分析的数据为例,从多个方面来探讨这一方面的内容。
关联分析要解决的主要问题是:一群用户购买了很多产品之后,哪些产品同时购买的几率比较高?买了A产品的同时买哪个产品的几率比较高?可能是由于最初关联分析主要是在超市应用比较广泛,所以又叫“购物篮分析”,英文简称为MBA,当然此MBA非彼MBA,意为Market Basket Analysis。
如果在研究的问题中,一个用户购买的所有产品假定是同时一次性购买的,分析的重点就是所有用户购买的产品之间关联性;如果假定一个用户购买的产品的时间是不同的,而且分析时需要突出时间先后上的关联,如先买了什么,然后后买什么?那么这类问题称之为序列问题,它是关联问题的一种特殊情况。从某种意义上来说,序列问题也可以按照关联问题来操作。
关联分析有三个非常重要的概念,那就是“三度”:支持度、可信度、提升度。假设有10000个人购买了产品,其中购买A产品的人是1000个,购买B产品的人是2000个,AB同时购买的人是800个。支持度指的是关联的产品(假定A产品和B产品关联)同时购买的人数占总人数的比例,即800/10000=8%,有8%的用户同时购买了A和B两个产品;可信度指的是在购买了一个产品之后购买另外一个产品的可能性,例如购买了A产品之后购买B产品的可信度=800/1000=80%,即80%的用户在购买了A产品之后会购买B产品;提升度就是在购买A产品这个条件下购买B产品的可能性与没有这个条件下购买B产品的可能性之比,没有任何条件下购买B产品可能性=2000/10000=20%,那么提升度=80%/20%=4。(http://bai.zhihao.blog.163.com/blog/static/5652272320118953220582/)
关联分析最经典的案例是沃尔玛的啤酒与尿布的故事:
沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,啤酒与尿布两件看上去毫无关系的商品会经常出现在同一个购物篮中。原来,年轻的父亲前去超市购买尿布的同时,往往会顺便为自己购买啤酒。
沃尔玛发现了这一独特的现象,开始在卖场尝试将啤酒与尿布摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物。而沃尔玛超市也可以让这些客户一次购买两件商品,而不是一件,从而获得了更多的销售收入。它向我们揭示商品之间是具有关联关系的,发现并利用这些商品之间的关联关系,可以在无法大幅增加门店客户数的前提下,通过增加购物篮中的商品数量达到增加销售额的目的,从而获得更大的经营收益。
商品相关性是指商品在卖场中不是孤立的,不同商品在销售中会形成相互影响关系,由于这种关系往往隐藏在数量庞大的商品群后面,平常我们无法发现,因此也称之为商品之间的“暗恋关系”。
那我们怎么让“暗恋关系”公开化呢?发现商品之间关联关系的方法,称为购物篮分析。对于传统零售业来说,要想进行商品的购物篮分析,需要采取一定的数据分析手段。
首先我们通过POS机收集的客户购物数据,找出哪些商品经常出现在同一个购物篮中。如果发现啤酒与尿布出现在同一个购物篮的概率比较高,就可以认为啤酒与尿布之间具有关联关系。这样就可以提示卖场的管理者,将原本看上去不搭界的啤酒与尿布两种商品陈列在一起,或者捆绑在一起促销,使这种“暗恋关系”起到促进销售的作用,使“暗恋关系”公开化。(《啤酒与尿布》)
我们的数据包括这些内容:
购物篮摘要:
• cardid.购买此篮商品的客户的忠诚卡标识符。
• value.购物篮的总购买价格。
• pmethod.购物篮的支付方法。
卡持有者的个人详细信息:
• sex
• homeown.卡持有者是否拥有住房。
• 收入
• age
购物篮内容 - 产品类别的出现标志,数据中T表示购买,F表示未购买:
• fruitveg
• freshmeat
• dairy
• cannedveg
• cannedmeat
• frozenmeal
• beer
• wine
• softdrink
• fish
• confectionery
利用Clementine的web网络作图功能,可以得到以下结果:
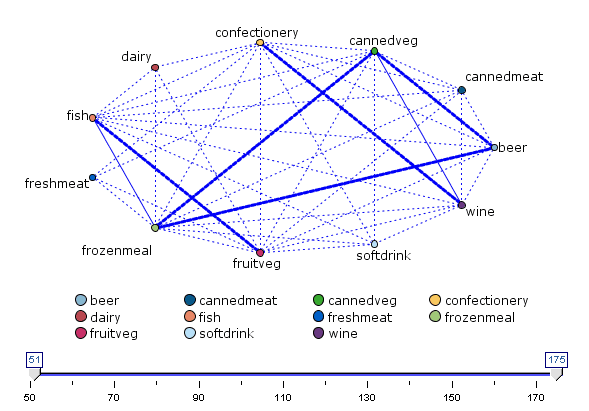
在对关系强度显示进行调整后,可以清晰的得到三个商品群体,可以理解为消费者更多地购买群体组合的产品,即同时购买同一群体内的产品。
这是采用GRI关联模型得到的结果:

结果和网络图观察到的结果基本一致。
利用数据挖掘的技术,此时我们还可以使用C5.0等相关算法对同一问题进行建模,并对建模结果进行主观评价和客观准确性验证。同时,我们可以将三类产品群体的购买消费者筛选出来,继续使用关联分析的方法,考察人口统计学变量对产品群体的影响,从而确定哪一类人群更喜爱同时购买哪些产品,为产品销售提供支持。
下面,我们忽略此数据的实际意义,仅考虑要对若干变量进行分类,不再考虑实际问题与统计方法的适合性,只看数据结构,使用传统的统计学数据分析方法,我们是不是仍然可以得出这些结论呢?
将数据导入到SPSS当中,将数据重新编码,原来的T、F用数字1、0来代替,因为1、0是可以运算的数字,可以参加多种的数学建模。
相关分析的结果:

聚类的结果:

因子分析的结果:

所有结论一致性都很高!
本文来源:OneCode
本文地址:https://cucldk.com/post/datamining-MarketBasketAnalysis.html
版权声明:如无特别注明,转载请注明本文地址!
